Cílem všech herních postupů je nalezení nebo predikce čísel, která budou vylosována v příštím tahu. Většina sázkařů sleduje nejčastěji nebo nejméně často losovaná čísla, analyzuje předchozí losování a/nebo jejich statistické vlastnosti a snaží se odhadnout, co se nejpravděpodobněji stane v příštím tahu.
Program Expert Lotto má vestavěný nástroj, který tyto predikce do jisté míry automatizuje. Program prohledá zvolená předchozí losování a porovnáním s několika posledními tahy provede predikci, která čísla a statistické vlastnosti je možné očekávat v příštím losování. Stejně jako všechny ostatní funkce programu jsou i predikce založeny na jednoduchých matematických výpočtech. Stejná vstupní data a stejná nastavení predikce vedou vždy ke stejným výsledkům. Nejedná se o žádnou magickou černou skříňku, která by při každém kliknutí generovala různé výsledky.
Predikce v Expert Lottu jsou založeny na porovnávání vzorků, což je algoritmus používaný i v jiných počítačových programech, jako je například statistické zpracování dat, rozeznávání tváří, zpracování signálu a další.
V následující tabulce je uvedeno 15 posledních losování ukázkové loterie Expert Lotto 6/49. Tahy jsou uvedeny v sestupném pořadí:
| Datum | Pozice 1 | Pozice 2 | Pozice 3 | Pozice 4 | Pozice 5 | Pozice 6 | Dodatkové |
| 2010/28 Ne 2nd | 23 | 29 | 36 | 42 | 44 | 47 | 7 |
| 2010/28 Ne 1st | 6 | 13 | 14 | 19 | 41 | 42 | 29 |
| 2010/28 St 2nd | 2 | 13 | 16 | 17 | 25 | 40 | 27 |
| 2010/28 St 1st | 16 | 18 | 22 | 23 | 28 | 29 | 24 |
| 2010/27 Ne 2nd | 1 | 6 | 12 | 24 | 32 | 41 | 44 |
| 2010/27 Ne 1st | 2 | 15 | 22 | 29 | 30 | 37 | 42 |
| 2010/27 St 2nd | 20 | 23 | 25 | 30 | 33 | 35 | 7 |
| 2010/27 St 1st | 8 | 11 | 19 | 26 | 48 | 49 | 18 |
| 2010/26 Ne 2nd | 8 | 11 | 18 | 32 | 36 | 38 | 6 |
| 2010/26 Ne 1st | 5 | 6 | 11 | 31 | 40 | 43 | 32 |
| 2010/26 St 2nd | 4 | 18 | 26 | 33 | 35 | 47 | 11 |
| 2010/26 St 1st | 5 | 12 | 25 | 31 | 44 | 46 | 33 |
| 2010/25 Ne 2nd | 10 | 15 | 28 | 30 | 36 | 43 | 35 |
| 2010/25 Ne 1st | 16 | 21 | 24 | 25 | 35 | 46 | 47 |
| 2010/25 St 2nd | 9 | 12 | 23 | 34 | 39 | 49 | 24 |
Poslední tři tažená čísla na druhé pozici tipu jsou: 13, 13 a 29. Tato tři čísla tvoří nejnovější vzorek. Protože vzorek obsahuje tři čísla, je jeho velikost 3.
Nyní projdeme předchozí losovaná čísla na druhé pozici tipu a budeme hledat stejný nebo alespoň podobný vzorek. Z výše uvedené tabulky je vidět, že vzorek s nejlepší shodou jsou tahy 2010/26 Ne 2nd až 2010/27 St 2nd. Jejich vylosovaná čísla jsou 11, 11 a 23. V následujícím tahu 2010/27 Ne 1st pak padlo na druhé pozici tipu číslo 15. Takže predikce pro druhou pozici tipu v příštím losovaní 2010/29 St 1st je číslo 15.
Nyní ověříme predikci v programu Expert Lotto:
Otevře se okno Vlastnosti vylosovaných čísel, které bude ve sloupečku Pozice 2 zobrazovat následující hodnotu:

Červený trojúhelníček směřující dolů indikuje, že trend predikovaný pro příští losování je pokles. Číselná hodnota predikce pro druhou pozici tipu je 15. Níže v textu naleznete podrobnější instrukce, jak správně interpretovat výsledky predikce.
Pokud necháme prediktor prohledat celou databází předchozích losování, pak najde vzorek s nejlepší shodou v tazích 2006/23 Ne 2nd až 2006/24 St 2nd, kdy padla čísla 12, 16 a 30. Následující výherní číslo na druhé pozici tipu je 11. To znamená, že predikovaný trend je také pokles a predikovaná hodnota je v tomto případě 11.
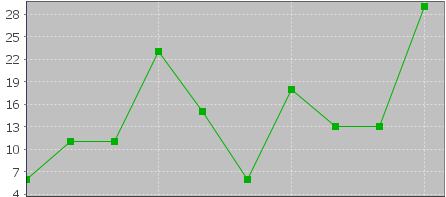
Co se stane, když rozšíříme velikost vzorku ze tří na 10 čísel? Nejnovější vzorek pak bude 6,11,11,23,15,6,18,13,13,29. Tato čísla zobrazená v grafu vypadají následovně:
Prediktor najde vzorek s nejlepší shodou v tazích 2008/45 Ne 2nd až 2008/48 St 1st, kdy padla čísla 9,20,13,21,12,8,15,15,4,27. Jejich graf vypadá následovně:
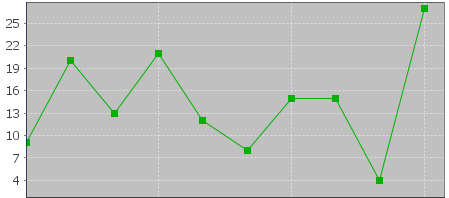
Následující číslo na druhé pozici tipu je opět 11 (tah 2008/48 St 2nd). To znamená, že predikovaný trend je znovu pokles a predikovaná hodnota je 11.
Porovnáním obou grafů vidíme, že podoba obou vzorků je pouze přibližná. Nicméně je to nejlepší shoda, kterou prediktor nalezl v celé databázi vylosovaných čísel. Není reálné očekávat, že v minulosti padla po sobě stejná čísla jako v posledních deseti tazích. S velikostí vzorků klesá míra shody mezi nejnovějším vzorkem a vzorkem s největší shodou. Jak tedy vybrat optimální velikost vzorku?
V příkladech výše jsme použili velikost vzorku 3, se kterou jsme získali predikovanou hodnotu 11, a velikost vzorku 10 taktéž s predikovanou hodnotou 11. V tomto případě byly výsledky predikce stejné. Co kdyby se ale predikované hodnoty nebo dokonce predikované trendy lišily? Jak zjistit, která predikce (velikost vzorku) je věrohodnější?
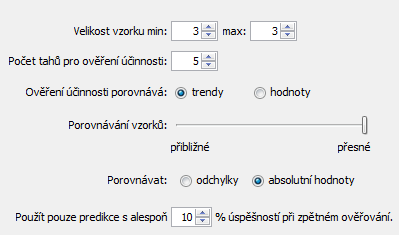
Prediktor provede sérii testovacích predikcí a zvolí optimální velikost vzorku automaticky. Volba Počet tahů pro ověření účinnosti v nastaveních predikce určuje hloubku tohoto testování. Pokud je pro predikci zvoleno například Velikost vzorku min: 3, max: 15, Počet tahů pro ověření účinnosti: 10, pak prediktor provede celkem 130 testovacích predikcí pro zvolení optimální velikosti vzorku. Začíná se s velikostí vzorku 3. Provede se predikce pro tah 2010/28 Ne 1st a predikovaný trend se porovná se skutečnou hodnotou následujícího tahu 2010/28 Ne 2nd. Pak se provede predikce pro tah 2010/28 St 2nd a trend se porovná s následujícím tahem 2010/28 Ne 1st. Celkem se provede 10 takovýchto predikcí až po tah 2010/26 St 2nd. Prediktor si poznamená, v kolika testech byl predikován správný trend v porovnání s následujícími tahy.
Pak se velikost vzorku zvýší na 4 a provede se dalších deset testovacích predikcí pro deset posledních losování. Znovu se zaznamená počet správně predikovaných trendů. Velikost vzorku se zvýší na pět a znovu se provedou testovací predikce. Takto se pokračuje až do velikosti vzorku 15, jak bylo zvoleno v nastaveních predikce. Prediktor poté vybere velikost vzorku, která měla nejvyšší počet správně predikovaných trendů. Tato optimální velikost vzorku se pak použije pro provedení vlastní predikce pro tah 2010/28 Ne 2nd.
Ve výše uvedeném příkladu je optimální velikost vzorku 3, protože při testování je sedm správně predikovaných trendů. Při velikosti vzorku 10 jsou správně pouze 4 predikce trendů z deseti provedených testů.
![]() Umístěním kurzoru myši nad políčko tabulky s výsledkem predikce se zobrazí bublinová nápověda ukazující optimální velikost vzorku a počet správně predikovaných trendů během testování.
Umístěním kurzoru myši nad políčko tabulky s výsledkem predikce se zobrazí bublinová nápověda ukazující optimální velikost vzorku a počet správně predikovaných trendů během testování.
Pomocí volby Ověření účinnosti porovnává hodnoty můžete algoritmus predikce změnit tak, že optimální velikost vzorku se vybere z testovacích predikcí, které byly nejblíže skutečné hodnotě.
![]() Pro některé loterie jsou dostupné dodatečné informace o každém losování - například jaká sada míčků byla použita, označení losovacího zařízení apod. Pokud se sada míčků nebo losovací zařízení mění v pravidelných intervalech, je patrně vhodné nepoužívat vzorky s velikostí větší, než je počet losování mezi takovýmito změnami.
Pro některé loterie jsou dostupné dodatečné informace o každém losování - například jaká sada míčků byla použita, označení losovacího zařízení apod. Pokud se sada míčků nebo losovací zařízení mění v pravidelných intervalech, je patrně vhodné nepoužívat vzorky s velikostí větší, než je počet losování mezi takovýmito změnami.
Prediktor nabízí dva způsoby porovnávání vzorků. Je možné srovnávat buď absolutní hodnoty v řadě čísel, jak je uvedeno výše, nebo je možné porovnávat odchylky čísel. Mějme následující řadu čísel:
31,35,13,20,15,5,2,10,4,25,3,10,5
Nechť poslední tři čísla řady tvoří nejnovější vzorek: 3,10,5. Při porovnávání absolutních hodnot je nalezena nejlepší shoda v číslech 2,10,4, za kterými pak následuje číslo 45. Avšak při porovnávání odchylek čísel je nejlepší shoda ve vzorku 13,20,15, který je následován číslem 5.
Pokud stejnou řadu čísel vyjádříme jako odchylky, bude vypadat následovně:
+31,+4,-22,+7,-5,-10,-3,+8,-6,+21,-22,+7,-5
Nejnovější vzorek je pak -22,+7,-5 a vzorek s nejlepší shodou pak je -22,+7,-5, což odpovídá číslům 13,20,15, za kterými následuje číslo 5.
Při porovnávání odchylek tedy musí mít shodující se vzorky stejný tvar (pořadí nárůstu/poklesu hodnot), nicméně absolutní hodnoty čísel mohou být navzájem posunuty nahoru nebo dolů.
Nyní zopakujeme predikci čísla na druhé pozici tipu s použitím porovnávání odchylek místo absolutních hodnot:
Vzorek s nejlepší shodou jsou tahy 2006/20 St 1st až 2006/20 Ne 1st s vylosovanými čísly 4,4,21. Těm odpovídají odchylky -3,0,+17 následované odchylkou -8.
Odchylky v nejnovějším vzorku jsou -5,0,+16. Predikovaná hodnota pak je:
29 – abs( -8 * (abs(-5/-3) + abs(0/0) + abs(16/17)) / 3 * ) = 29 – 9.62 = 19
Všimněte si, že predikovaná hodnota je posunuta tak, aby se vzaly v úvahu rozdíly ve velikosti odchylek v nejnovějším vzorku a ve vzorku s nejlepší shodou.
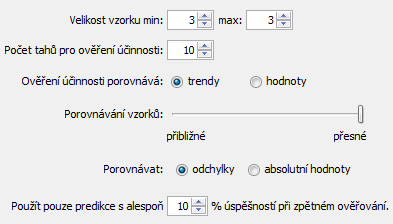
Stejná predikce pro velikost vzorku 10 najde nejlepší shodu v tazích 2009/24 St 1st až 2009/26 St 2nd, kde jsou čísla 5,15,15,20,13,10,14,9,6,11 následovaná číslem 21. Predikce je pak nárůst na hodnotu 46. Tato predikce je v rozporu s predikcí pro velikost vzorku 3. Nicméně se jedná o něco méně věrohodnou predikci, protože pouze 5 testovacích predikcí bylo správných. Při ověřování velikosti vzorku 3 bylo správných 6 predikcí z deseti.
![]() Porovnávání odchylek je vhodné zejména pro predikci odvozených hodnot, jako jsou například součty a odchylky Historie. Porovnávání absolutních hodnot se hodí spíše pro hodnoty s menším rozsahem, jako jsou základ sumy, lichá/sudá nebo vylosovaná čísla na jednotlivých pozicích tipu.
Porovnávání odchylek je vhodné zejména pro predikci odvozených hodnot, jako jsou například součty a odchylky Historie. Porovnávání absolutních hodnot se hodí spíše pro hodnoty s menším rozsahem, jako jsou základ sumy, lichá/sudá nebo vylosovaná čísla na jednotlivých pozicích tipu.
Posuvník Porovnávání vzorků v okně Možnosti Predikce určuje jakou váhu mají jednotlivá čísla při porovnávání vzorků. Je-li posuvník zcela vpravo, je porovnávání vzorků přesné a každé číslo vzorku má stejnou váhu.
Posuntím doleva se kritéria pro porovnávání vzorků sníží neboť čísla porovnávaných vzorků budou mít nižší váhu. Jestliže je nejnovější vzorek například 6,11,11,23,15,6,18,13,13,29, pak při přesném porovnávání nalezne prediktor nejlepší shodu například ve vzorku 9,20,13,21,12,8,15,15,4,27. Při přibližném porovnávání vzorků bude nejlepší shoda například se vzorkem 33,16,25,14,31,11,18,12,16,30. Je vidět, že podobnost několika prvních čísel obou vzorků je pouze velice přibližná. V obou případech je predikována hodnota 10. Avšak v případě přibližného porovnávání vzorků bude 9 správných ověřovacích predikcí, při přesném porovnávání vzorků bude pouze 7 správných ověřovacích predikcí při zpětném testování na 15 posledních tazích. Přibližné porovnávání vzorků je doporučeno pouze pro vyšší velikosti vzorků (10 a více).
Predikce jsou dostupné z menu Vylosovaná čísla – Predikce nebo z menu Historie – Predikce. V obou případech se tak spouští průvodce Predikce.
Průběh predikce je možné sledovat v pravém dolním rohu hlavního okna programu. Po dokončení jsou výsledky predikce zobrazeny v oknech Vlastnosti vylosovaných čísel a Grafy vylosovaných čísel nebo v okně Historie součtů pod záložkami Součty a Grafy.
![]() – modrý trojúhelník označuje, že predikovaný trend je nárůst. Očekává se tedy, že hodnota příštího tahu bude vyšší než poslední hodnota. V políčku tabulky je také zobrazena vlastní predikovaná hodnota.
– modrý trojúhelník označuje, že predikovaný trend je nárůst. Očekává se tedy, že hodnota příštího tahu bude vyšší než poslední hodnota. V políčku tabulky je také zobrazena vlastní predikovaná hodnota.
![]() – červený trojúhelník označuje, že predikovaný trend je pokles. Očekává se tedy, že hodnota příštího tahu bude nižší než aktuální hodnota.
– červený trojúhelník označuje, že predikovaný trend je pokles. Očekává se tedy, že hodnota příštího tahu bude nižší než aktuální hodnota.
![]() – červený trojúhelník spolu s modrým trojúhelníkem označují, že predikovaný trend je shoda. Očekává se tedy, že příštím losování padne stejná hodnota jako v posledním tahu.
– červený trojúhelník spolu s modrým trojúhelníkem označují, že predikovaný trend je shoda. Očekává se tedy, že příštím losování padne stejná hodnota jako v posledním tahu.
Poznámka: Prediktor zpracovává pouze řadu čísel a "neví", jaké závislosti pro danou řadu čísel platí. V některých případech se může stát, že predikovaná hodnota je nižší nebo vyšší než maximální nebo minimální možná hodnota. V takovém případě je doporučeno zvažovat pouze predikovaný trend.
Hodnota n/a znamená, že nebylo možné provést platnou predikci. Obvykle proto, že není k dispozici dostatek vstupních dat, aby bylo možné najít shodující se vzorky.
![]() Predikovaný trend by měl být hlavním indikátorem při přípravě sázky na příští losování. Vlastní predikovaná hodnota pouze naznačuje, jak velký je očekávaný nárůst nebo pokles.
Predikovaný trend by měl být hlavním indikátorem při přípravě sázky na příští losování. Vlastní predikovaná hodnota pouze naznačuje, jak velký je očekávaný nárůst nebo pokles.
Umístěním kurzoru myši na políčko tabulky s výsledky predikce se zobrazí bublinová nápověda s doplňujícími informacemi. Můžete tak vidět, kolik testovacích predikcí bylo správných a jaká velikost vzorku byla zvolena pro provedení predikce.
![]() Je doporučeno ignorovat výsledek predikce, jestliže má malé procento správných testovacích predikcí. Toho lze dosáhnout zadáním požadovaného procenta úspěšnosti při zpětném ověřování do posledního vstupního políčka.
Je doporučeno ignorovat výsledek predikce, jestliže má malé procento správných testovacích predikcí. Toho lze dosáhnout zadáním požadovaného procenta úspěšnosti při zpětném ověřování do posledního vstupního políčka.
Podrobné informace o provedených predikcích jsou dostupné v Protokolu programu. Po dokončení predikce zvolte menu Zobrazit – Protokol programu. V okně Výstup se pak zobrazí následující podrobnosti ke každé predikované hodnotě. Například:
Pozice 2 – název predikované hodnoty. V tomto případě se jedná o predikci vylosovaného čísla na druhé pozici tipu.
Trend prediction: Decrease – predikovaný trend (increase - nárůst / decrease - pokles / level - shoda)
Predicted value: 10.0 – vlastní predikovaná hodnota. Všechny hodnoty jsou počítány od nuly, takže predikované vylosované číslo je 11.
Best pattern size: 5 – velikost vzorku použitá při predikci.
Best weight: 1.0 – váha čísel použitá při predikci. Pokud se nenavolí přibližné porovnávání vzorků, je váha vždy 1.0.
Matching pattern: [10.0 17.0 11.0 15.0 29.0] => 10.0 – vzorek s nejlepší shodou. V tomto případě jsou čísla vzorku 11,18,12,16,30. Číslo následující za tímto vzorkem je 11.
Marker: 94 – pozice v řadě čísel, kde byl nalezen vzorek s nejlepší shodou. Hodnota 0 znamená nejstarší tah ve zvoleném výběru vylosovaných čísel.
Back-tests: 15 – počet ověřovacích predikcí, které byly provedeny pro zvolení optimální velikosti vzorku.
Mean Square Error: 107.66666666666667 – ukazuje, nakolik se ověřovací predikce liší od skutečných hodnot. Čím nižší je hodnota MSE , tím přesnější byly ověřovací predikce.
Mean Absolute Percentage Error: 0.6399601052542229 - MAPE indikátor také porovnává ověřovací predikce se skutečnými hodnotami.
Valid trend predictions: 6 (40.0%) - udává procento ověřovacích predikcí, které správně předpověděly trend.
Viz také filtr Prediktor trendů.